【瞎扯】Instagram爬虫编写过程 附源码
前言
昨天把ins上一个美图博主的图片爬了下来,@zeewipark 就是Ta(不知道性别...)啦~
为啥要爬下来可以看下昨天的文章链接:https://b.julym.com/share/719.html
昨天用易语言写的爬虫,今天早上用java写了出来,刚好分享出来还能水一篇文章 :tv39:
正文
首先,确定要爬的主页链接,以@zeewipark 为例,主页链接为:https://www.instagram.com/zeewipark/。
打开后我们按下f12调开发者工具出来选择Network 开始抓包,刷新一下,鼠标直接点XHR分类(也就是XMLHttpRequest ),这样可以直接看到ins使用AJAX请求了哪些数据接口。
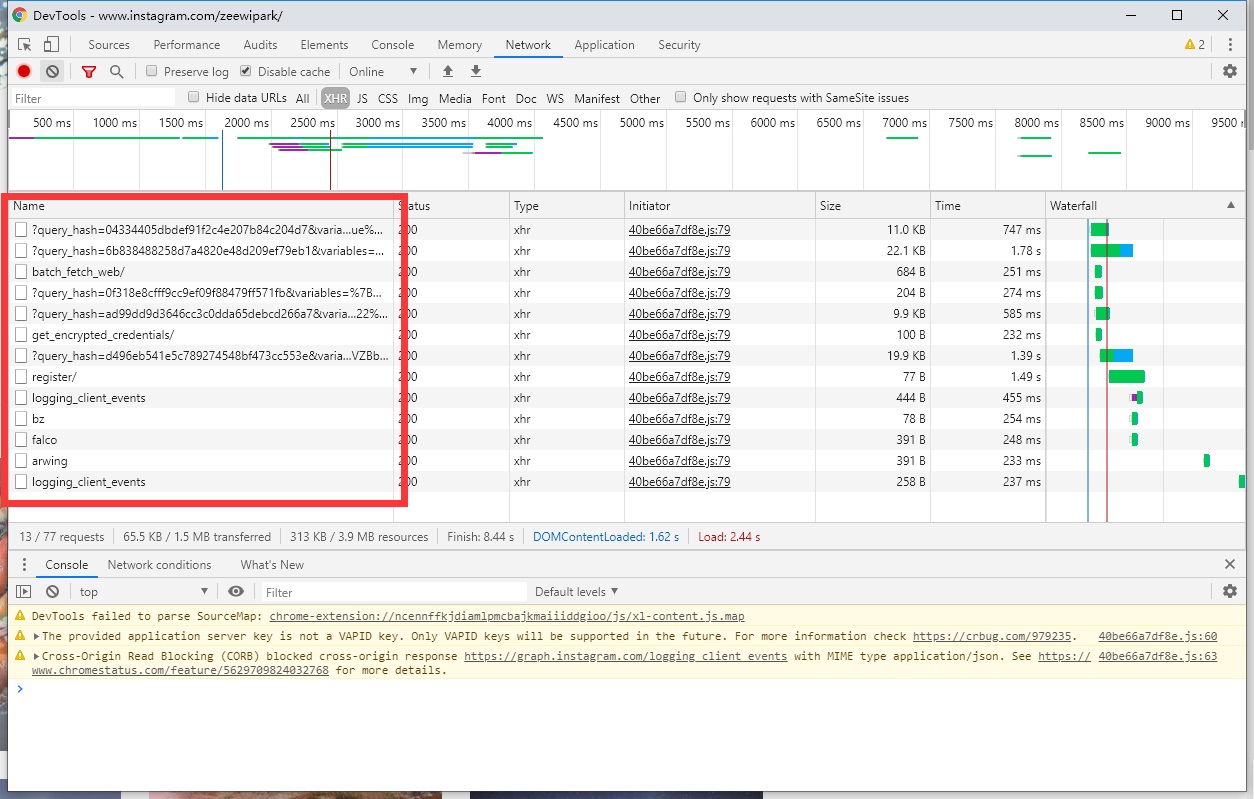
依次查看这几个请求的返回数据发现在这一个Get请求中返回了部分ta主页的图片url(链接)。
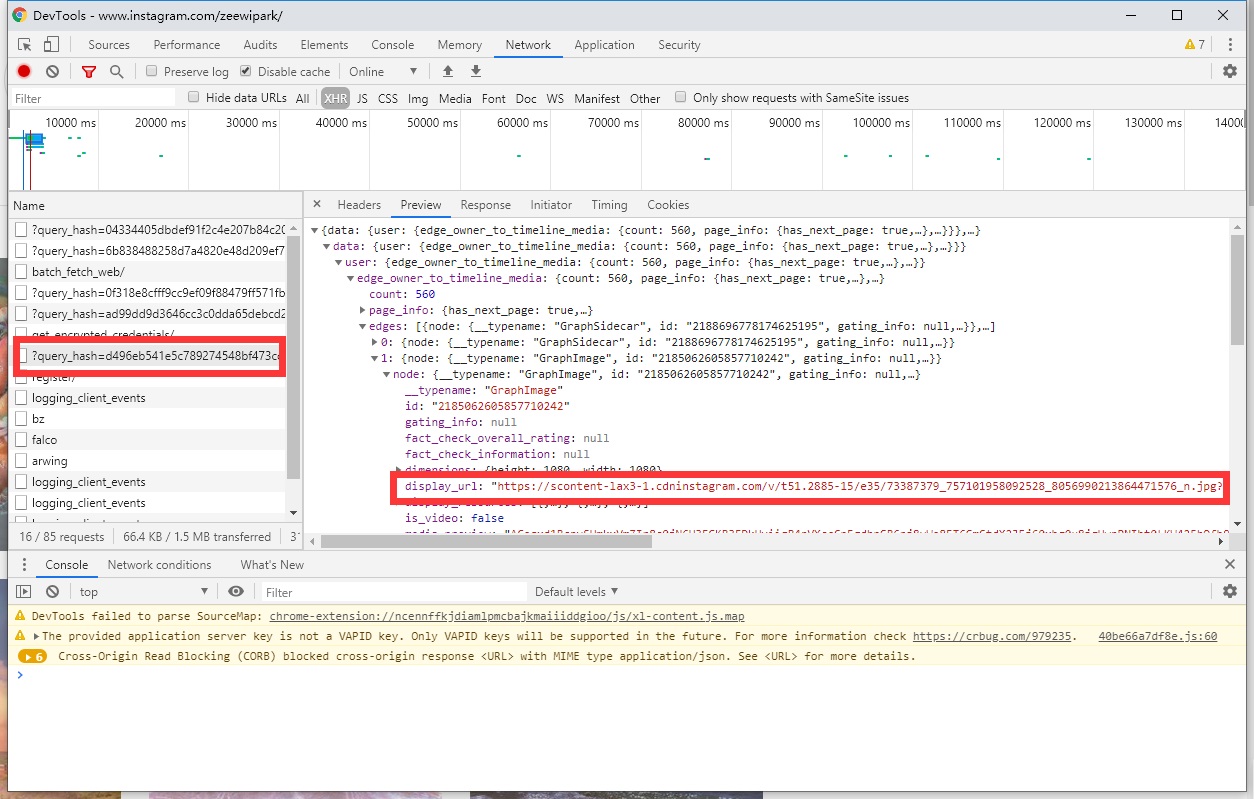
复制到浏览器访问发现可以显示出图片,但不是第一张,这时候仔细看看请求头的参数,除了query_hash外还附带了一串url编码过的json字符串。

id应该是这个博主的一个id,看到first是12,可能指的就是从哪里开始返回数据,12就是从第12张图后开始返回,还有一个after,看起来像是base64编码后的数据,这时候不要着急,继续往下滑网页(Instagram一次只加载一部分数据),
在加载出新图片的同时,调试工具再次出现了?query_hash_d496e开头的请求,那么就证明图片确实是从这一个接口请求出来的。但这时候发现请求参数中的after出现了变化,其他没有变化。


前后对比一下这两个请求返回的数据,发现了第一次请求返回中的json字符串中有这一段数据,等等,这不是对应了第二次返回的after参数吗?
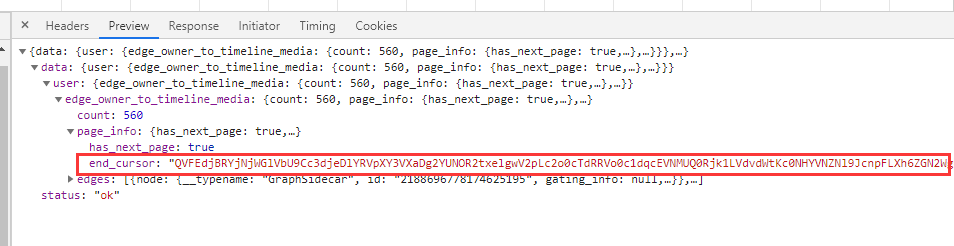
再根据这些参数名 page_info has_next_page after end_currsor的设定,可以判断出after参数应该是一个位置标识,请求这个位置标识之后的数据。query_hash 应该是一个用博主的id之类的加密出来的一个特定值(因为我昨天抓包到今天抓包 这个参数不变),而count刚好对应上这个博主的文章数量。

那么有了这些数据的话就可以开始理清思路写代码了。
分析返回的json字符串得知每次返回的图片只有12张,那么560张总共需要返回560/12=46.6≈47次。
那就写一个for循环,循环请求这个URL47次,每一次请求保存下after的值给下一次请求做参数。然后在for循环中再写一个for循环遍历json里的数组 取出12张图片的url再保存下来。
以下代码需要一个http请求类一次一个json解析类(第三方类 需要网上下载后引入项目)
Java 源代码以及Http请求类、Json类下载地址:点我下载
易语言 源代码:点我下载
易语言的用了本地的socks5代理,记得自行修改或去掉。
python用request包就可以了
php直接用自带的file_get_contents就行 或者 curl
(当然 如果写成多线程的话会快很多倍)
效果图:
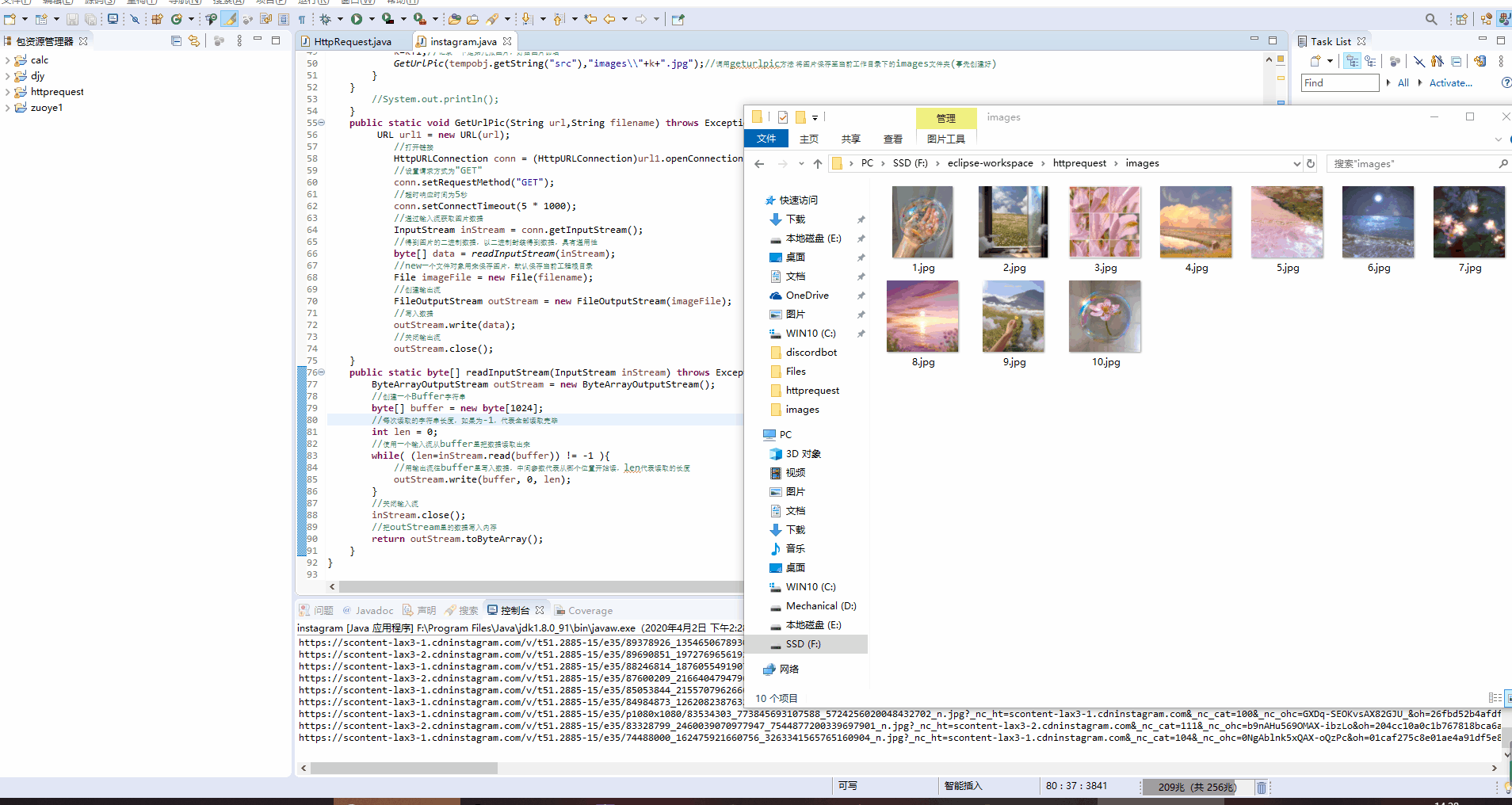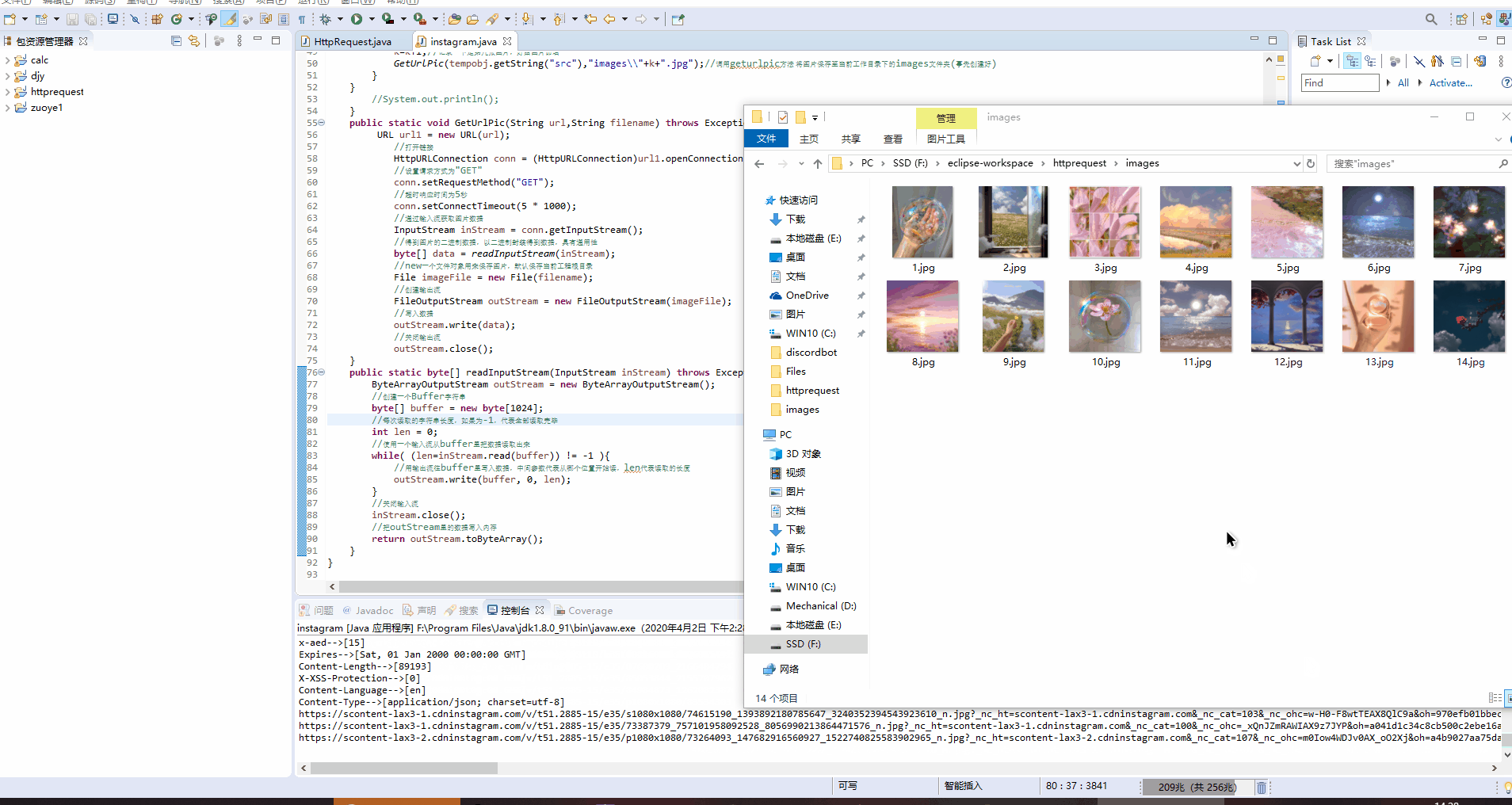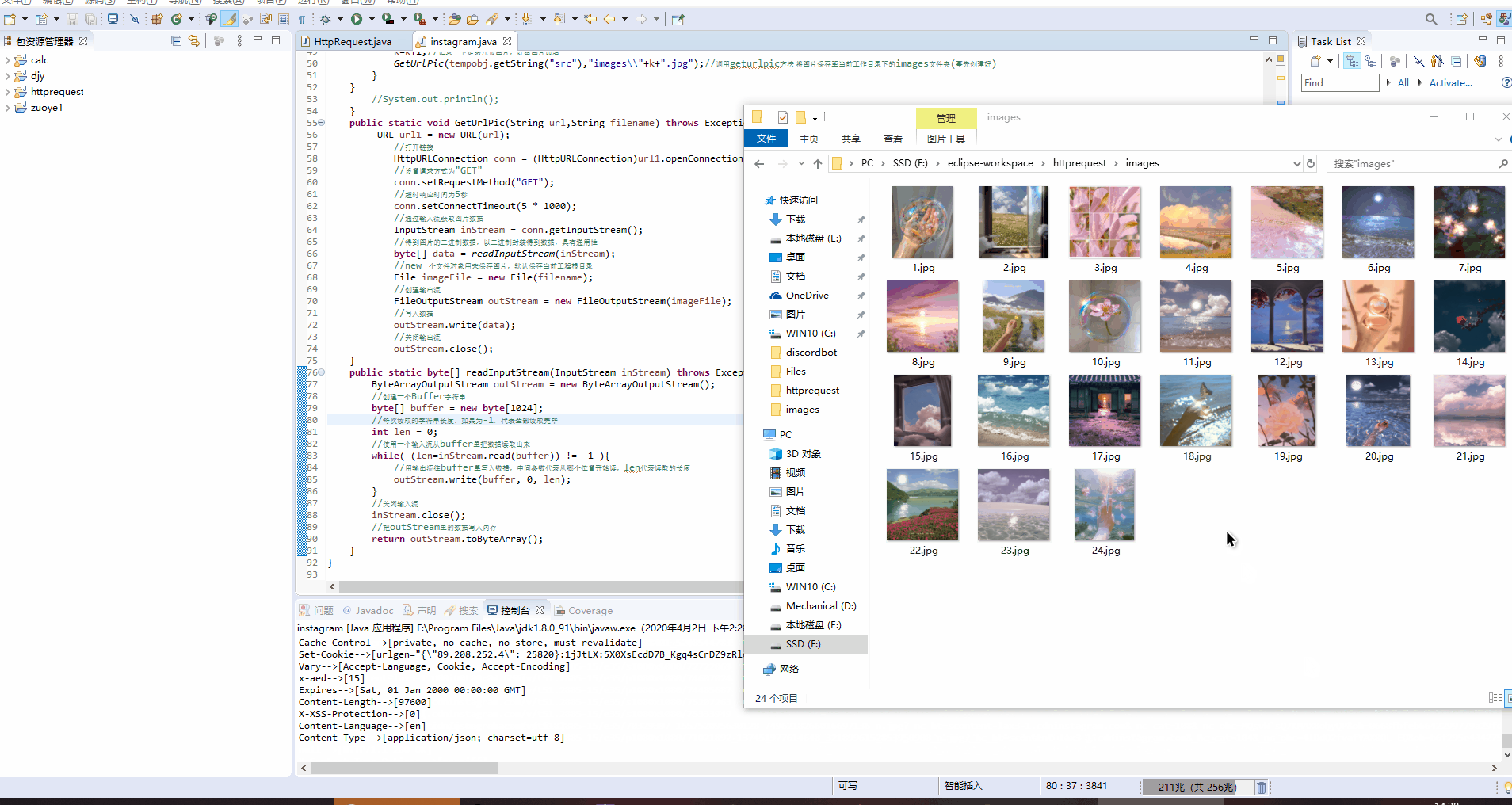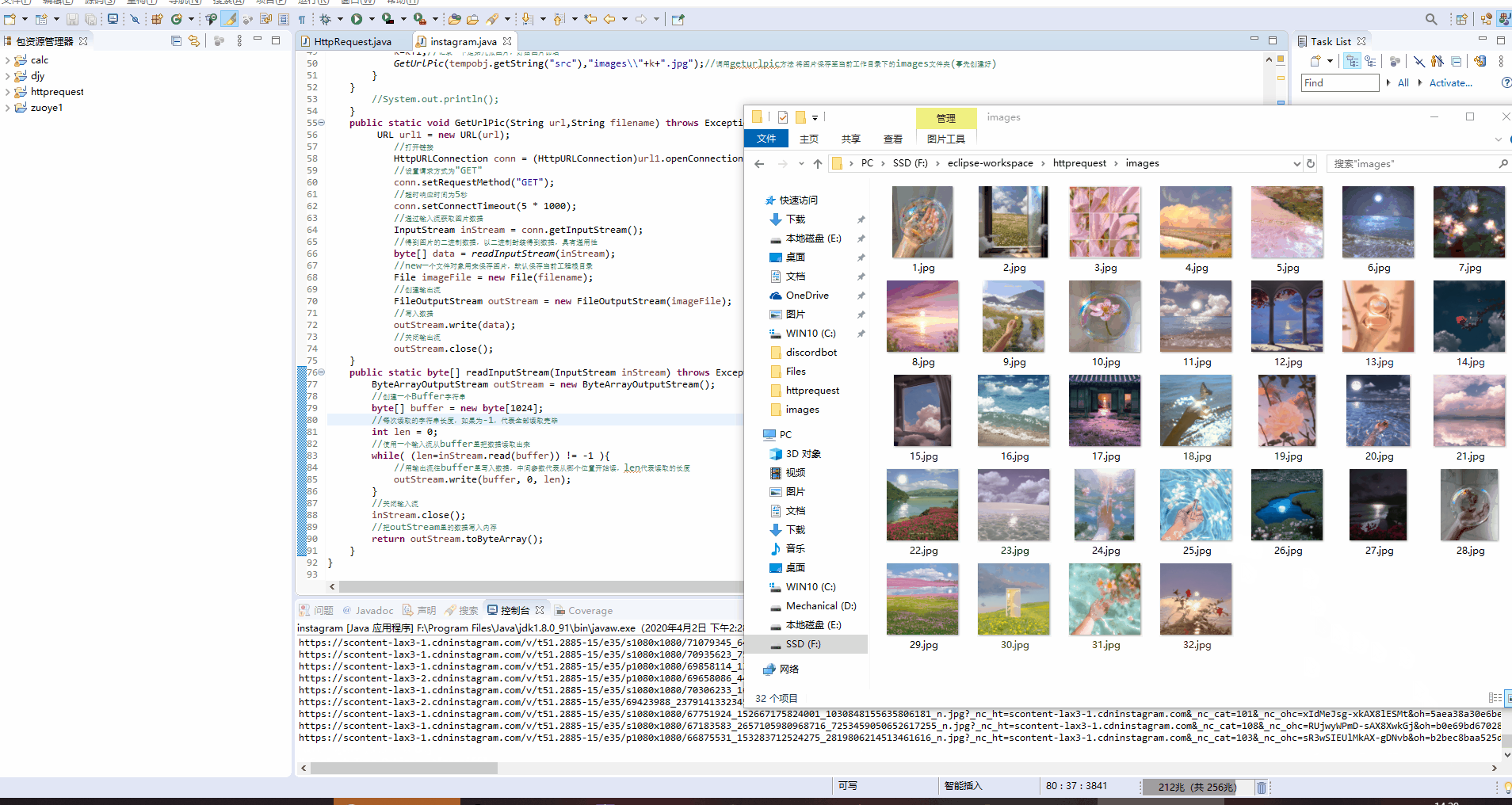
具体代码如下:
package httprequest;
import java.io.UnsupportedEncodingException;
import org.json.JSONException;
import org.json.JSONObject;
import org.json.JSONArray;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
public class instagram {
public static void main(String[] args) throws Exception {
// TODO 自动生成的方法存根
String str;//保存每次请求接口返回的数据
int i,j,k = 0;//i,j用于循环体记录,k用来给图片做文件名
String variables;//保存位置标识参数的变量
JSONObject json = null;//json对象 解析json字符串
variables = "%7B%22id%22%3A%2214847010%22%2C%22first%22%3A0%2C%22after%22%3A%22QVFEUEtZMnhHQmhicHNmVVN0ejVzU1dIamtOWWVSb0kyVmx0bmlzdjVWcEx3bmhMLWtoZTF0bkNDWm91WGRxbEhnZlh3M3E1bXJXM0ladWVxdVRnQ3AxYg%3D%3D%22%7D";
//第一次请求的after参数
String json1 = "{\"id\":\"14847010\",\"first\":12,\"after\":\"";//有斜杠是因为json字符串里有"号,而java使用"包裹字符串,所以需要使用\斜杠把"转义为原来的字符含义
String json2 = "\"}";//json1和json2用于给after参数拼接json字符串
String url = "https://www.instagram.com/graphql/query/?query_hash=d496eb541e5c789274548bf473cc553e&variables=";//设置请求的url
HttpRequest http = new HttpRequest();//实例化一个http类
for (j=0;j<47;j++) {//开始循环47次,因为总共560张图,每次返回12张,需要循环560/12=46.66≈47次
str = http.sendGet(url+variables);//发起Get请求,将variables拼接至url后
json = new JSONObject(str);//json解析返回的结果
JSONObject json3 = json.getJSONObject("data");
json3 = json3.getJSONObject("user");
json3 = json3.getJSONObject("edge_owner_to_timeline_media");
json3 = json3.getJSONObject("page_info");
//一步一步解析出end_cursor(也就是after参数的值),用作下一次请求的参数
variables = java.net.URLEncoder.encode(json1 + json3.getString("end_cursor")+json2,"UTF-8");//java.net.URLEncoder.encode为拼接好的variables参数进行url编码
json3 = json.getJSONObject("data");
json3 = json3.getJSONObject("user");
json3 = json3.getJSONObject("edge_owner_to_timeline_media");
JSONArray edges = json3.getJSONArray("edges");
//解析出包含图片url的json数组并复制给edges
for(i=0;i<edges.length();i++) {//开始循环 edges.length()为取这个数组的成员数量,文章里说了每次只返回12张图片链接,但保险起见还是循环成员总数量的次数
JSONObject tempobj = (JSONObject) edges.get(i);//取到图片的json对象复制给临时Json类 tmpobj
JSONObject tempobj1 = tempobj.getJSONObject("node");//因为图片在node对象,所以去出node对象并复制给临时json对象 tempobj1
JSONArray temparr = tempobj1.getJSONArray("display_resources");//取出包含图片url的数组,一般有三个成员,因为图片有三种大小
tempobj = (JSONObject) temparr.get(2);//直接去第三个,因为是最清晰的
System.out.println(tempobj.getString("src"));//控制台输出一下url链接
k=k+1;//记录一下是第几张图片,好给图片命名
GetUrlPic(tempobj.getString("src"),"images\\"+k+".jpg");//调用geturlpic方法 将图片保存至当前工作目录下的images文件夹(事先创建好)
}
}
//System.out.println();
}
public static void GetUrlPic(String url,String filename) throws Exception {
URL url1 = new URL(url);
//打开链接
HttpURLConnection conn = (HttpURLConnection)url1.openConnection();
//设置请求方式为"GET"
conn.setRequestMethod("GET");
//超时响应时间为5秒
conn.setConnectTimeout(5 * 1000);
//通过输入流获取图片数据
InputStream inStream = conn.getInputStream();
//得到图片的二进制数据,以二进制封装得到数据,具有通用性
byte[] data = readInputStream(inStream);
//new一个文件对象用来保存图片,默认保存当前工程根目录
File imageFile = new File(filename);
//创建输出流
FileOutputStream outStream = new FileOutputStream(imageFile);
//写入数据
outStream.write(data);
//关闭输出流
outStream.close();
}
public static byte[] readInputStream(InputStream inStream) throws Exception{
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
//创建一个Buffer字符串
byte[] buffer = new byte[1024];
//每次读取的字符串长度,如果为-1,代表全部读取完毕
int len = 0;
//使用一个输入流从buffer里把数据读取出来
while( (len=inStream.read(buffer)) != -1 ){
//用输出流往buffer里写入数据,中间参数代表从哪个位置开始读,len代表读取的长度
outStream.write(buffer, 0, len);
}
//关闭输入流
inStream.close();
//把outStream里的数据写入内存
return outStream.toByteArray();
}
}

原文链接:【瞎扯】Instagram爬虫编写过程 附源码
Macro's Blog 版权所有,转载请注明出处。




 好用就行
好用就行 ,时光荏苒啊。
,时光荏苒啊。

还没有任何评论,你来说两句吧!