【Python】微博爬虫代码详解
前言
昨天发了篇新文章,爬虫爬了九万多张微博图片。因为有人说,所以在这里解释一下编写过程。(nice 又水一篇文章)
昨天的地址: https://b.julym.com/original/1024.html
请求与数据分析
以此 博主 链接为例:https://weibo.com/u/6926803863
打开开发者工具进入这个网址,然后直接搜索出现的图片文件名以用来查找微博请求图片数据的 请求记录。
但是直接就是在这个页面的.html写死的(服务器生成后返回的),这样不利于我们爬虫爬取数据(整个html页面太大 请求过于耗时)
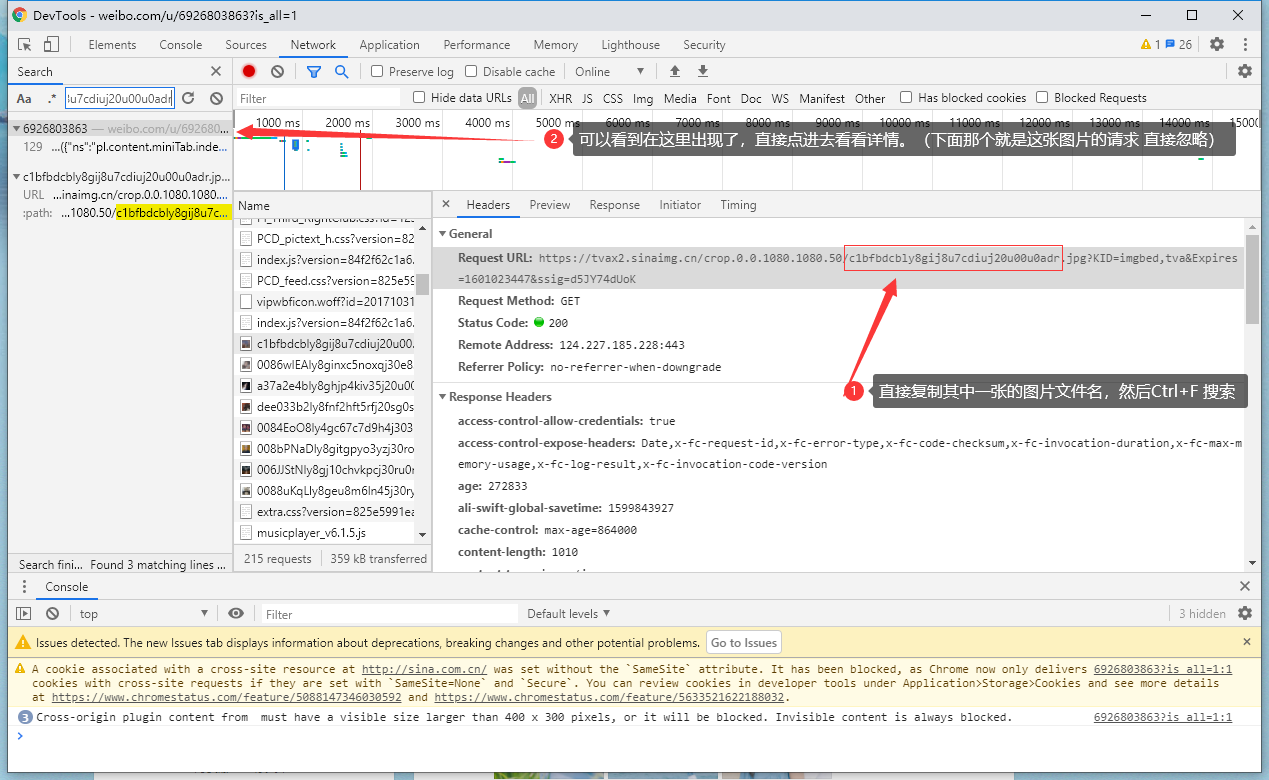
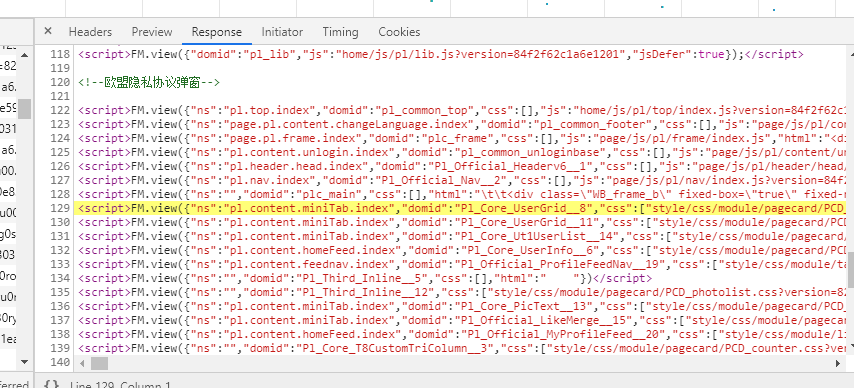
所以这个时候我们点击开发者工具的左上方的第二个按钮,将目前协议头改为手机,然后刷新页面,说不定微博手机版页面会有惊喜 (如果没有的话就只能爬pc的页面了)
(如果没有的话就只能爬pc的页面了)
还是和上面一样的方法,搜索图片文件名以此查找请求图片数据的记录。
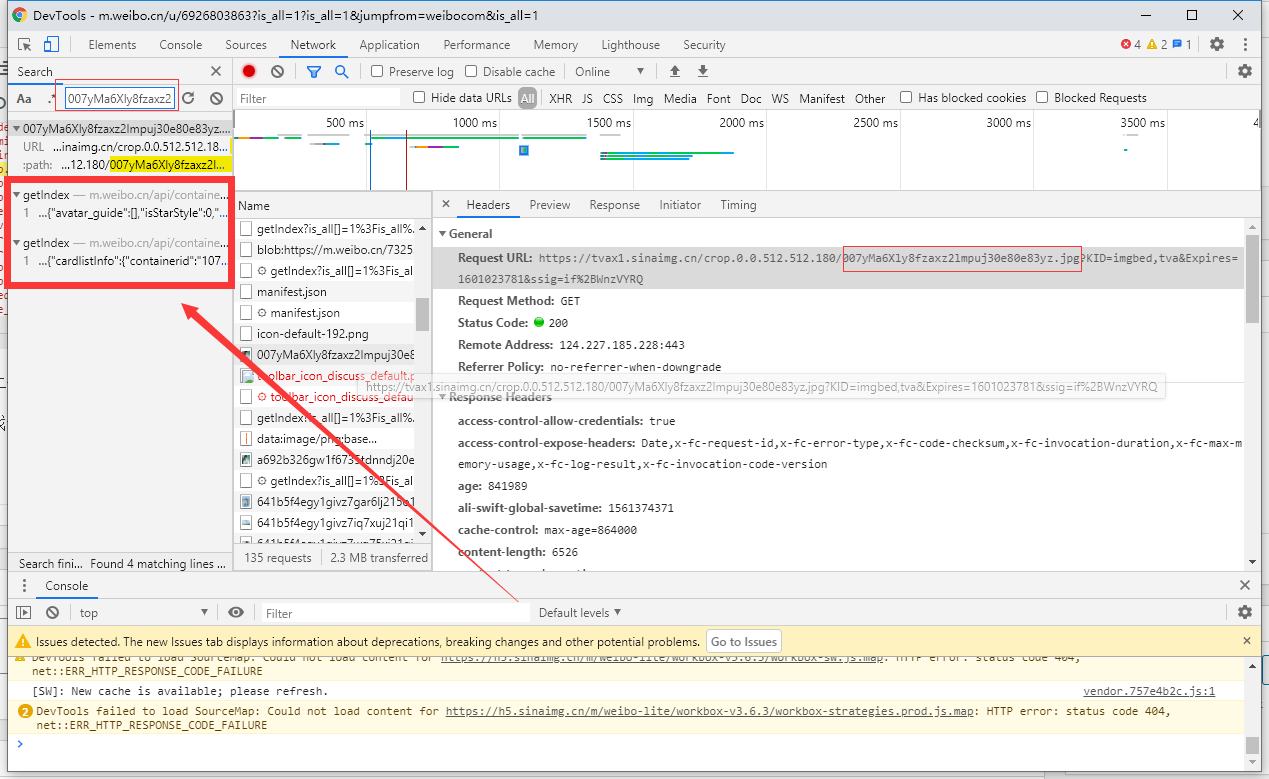
看到有两个请求返回了图片数据,看了下第一个的请求数据,只有一张图片数据,那就果断看第二个结果的请求数据,看到有大概九十张图片的返回结果。
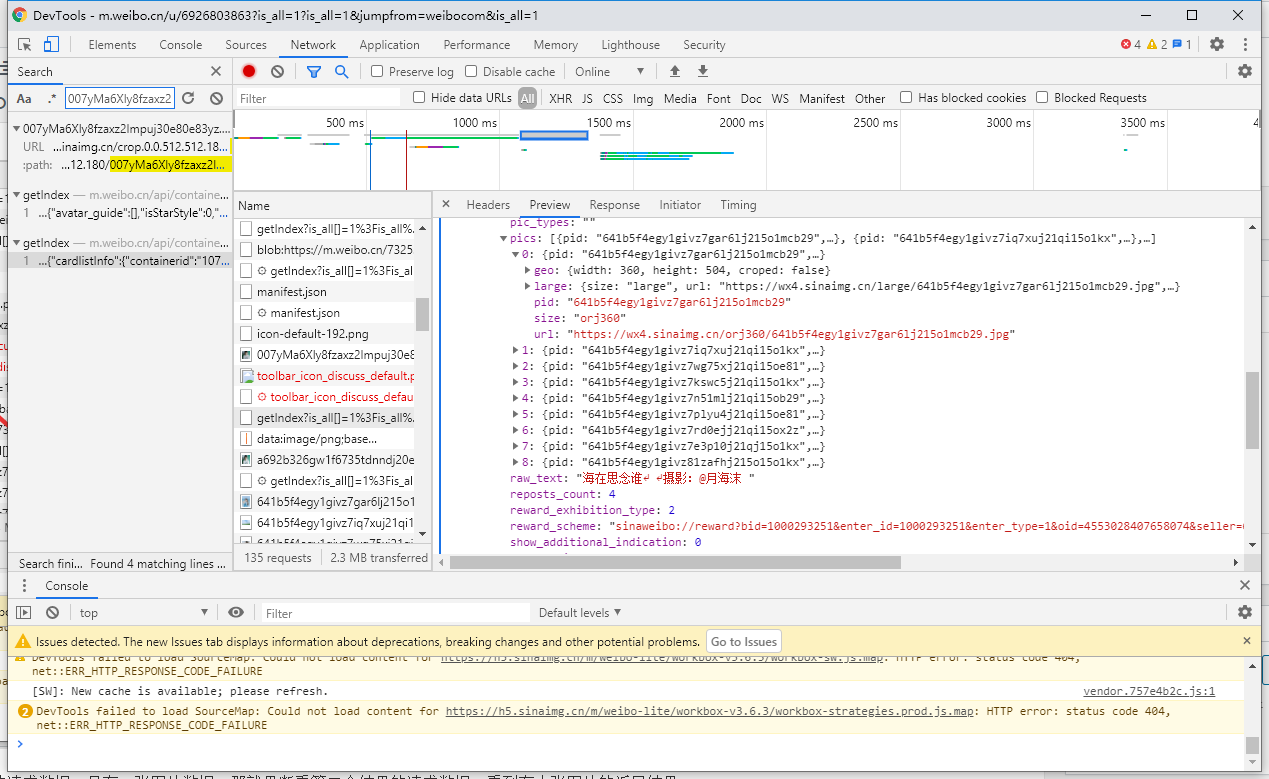
这个请求的返回内容就是一段json(太长了,这里不放出来这段json了。),我们需要的图片数据在 data 对象 中 的 cards数组,这个cards数组有十个成员,图片就存在每个成员的mblog -> pics数组中,那就说明一个cards成员对应一条微博,那我们怎么获取除这十条以外的微博嘞?
鼠标继续往下滑,然后关注开发者工具,在微博页面加载出新微博的时候就可以在开发者工具看到 它 加载下面十条微博(说明手机版页面每次加载十条微博)的请求记录了。
对比两次请求URL(因为是get请求 post请求还需要对比post数据)
对比两次请求分析URL参数结果如下:
is_all[]=1%3Fis_all%3D1&is_all[]=1&jumpfrom=weibocom 为无用参数 可以剔除也可以保留
type=uid 应该是说明根据uid请求,因为后面有一个value参数就是 这个博主的 uid 你可以在Ta的微博地址中发现,也可以在html源代码中发现
https://weibo.com/u/6926803863
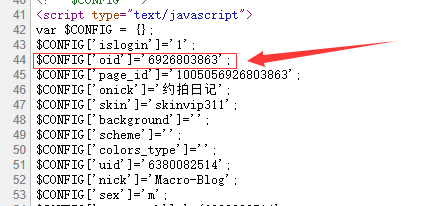
那就剩下两个参数了,一个是containerid 一个是 since_id。
containerid顾名思义应该就是存放这个用户微博数据的一个id 地址(因为我发现这个没有这个id是没办法正常返回数据的,而且 在不改变用户微博的情况下不会改变,所以应该是一个恒定的常量。)
since_id 顾名思义应该就是一个记录位置信息的参数,比如说告诉服务器你上一次请求的位置然后服务器就会返回给你下一次的位置(下面会说)
还是老方法,把这两个参数的值放到开发者工具中搜索。
搜索containerid的值发现 containerid是存在于你访问这个微博页面的时候 服务器返回给你的Cookie当中(在Response Header返回头中Set-Cookie就是服务器为你设置的cookie)
那么containerid我们就可以通过get请求获取cookie来获取。
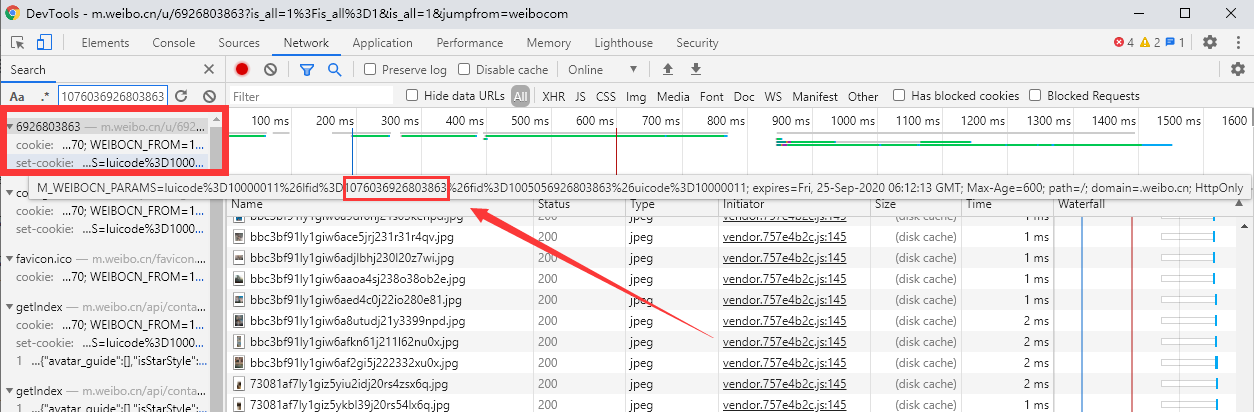
搜索since_id 发现来自第一次的请求数据中,那我在上面的说法就没错了,每一次请求都附带上一次返回的位置信息(上次爬Instagram也是这样,这是一个常见的做法了。)
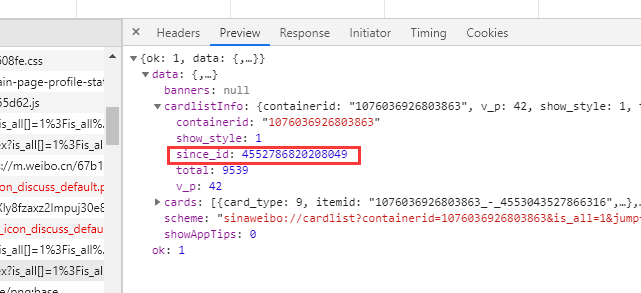
至此最主要的一步我们就分析完成了,接下来分析返回的json数据。
total应该就是指 用户微博数量(但是和微博显示出来的一样,显示出来是9547条,数据中显示是9539条,可能有私密微博啥的?。。不过这个不影响)
然后since_id就是用做下一次请求的参数
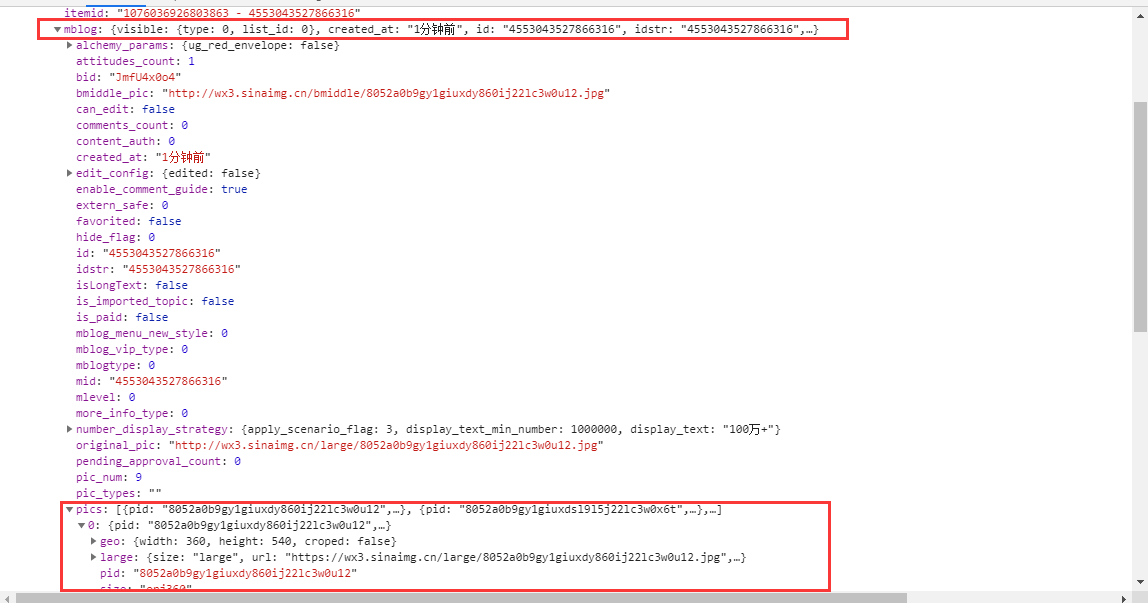
cards 数组就是每一次请求返回的微博,图片在每一个cards成员中的mblog对象中的pics数组。
pics数组中存放着所有和本次微博相关的图片信息,large中存放的就是大图了,所以我们每次爬取的时候都爬取large中的图片url(不然不清晰啊老哥!)。
代码编写
写代码前先清晰一下编写过程。
- 首先需要有博主的uid
- 其次需要获取containerid
- 最后每一次请求附带上一次返回的since_id 即可一直爬取下去
那我们就需要 os, urllib, requests, json 三个库,没有的话就pip安装一下
(懒人复制区)
pip install requests pip install urllib pip install json
开始编写,先引用相关库, 定义相关变量。
import _thread
import os
from urllib import parse
import requests
import json
import urllib
# 引用相关库, urllib用于url编码解码 以及 保存图片。
# json库用于解析获取到的图片json数据
# requests就不用说了,进行http请求
# os 用于获取文件名
# _thread 可以用来进行多线程
save_path = 'D:/weibo_images/' #定义保存路径变量
weibo_id = '6926803863' #需要爬取的微博账号ID
download = 0 #是否保存图片 0为不保存
total_count = 0 #记录总共爬取的图片数量
#定义请求协议头 用于http请求
headers = {
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Mobile Safari/537.36',
}
获取containerid 以及 总共微博数量 函数
def get_ContainerIDAndCount_Fromcookie(id):
global headers
request = requests.get('https://m.weibo.cn/u/'+id,headers=headers)#根据weibo_id拼接请求url get请求后从cookie中获取containerid
#request.raw.headers.getlist('Set-Cookie')
containerID = parse.unquote(request.cookies['M_WEIBOCN_PARAMS']).split('=')[1].split('&')[0] # containerid在 M_WEIBOCN_PARAMS cookie中 利用split将其分割获取出来
request = requests.get('https://m.weibo.cn/api/container/getIndex?type=uid&value='+ id +'&containerid=' + containerID, headers=headers) #获取一下总共微博数
json_temp = json.loads(request.text)#解析json
containerid = json_temp['data']['tabsInfo']['tabs'][1]['containerid']#这行可以不要 也是获取containerid的
request = requests.get("https://m.weibo.cn/api/container/getIndex?containerid=" + containerid,headers=headers)
json_temp = json.loads(request.text)#json 解析
count = json_temp['data']['cardlistInfo']['total']#获取总微博数
return containerid,count #返回containerid以及微博数
containerID, weibo_count = get_ContainerIDAndCount_Fromcookie(weibo_id) #调用获取containerid和weibo_count的函数
保存下载图片的函数
def saveImage(url):
global total_count, download#全局引用total_count和download 进行计数和判断是否保存
total_count += 1 #自增1
file = 'url.txt' # 把url 保存到当前目录的url.txt 文件中
with open(file, 'a+') as f:
f.write(url + '\n')
try:#使用try避免网络问题失败
if (download == 1):#如果download = 1的话就保存图片 不然就仅仅保存url
urllib.request.urlretrieve(url, save_path + os.path.basename(url))
print("正在下载第:{0}张 \n {1}".format(total_count,url))
except:
print("下载失败,重新下载。")
if (download == 1):
urllib.request.urlretrieve(url, save_path + os.path.basename(url))
print("正在下载第:{0}张 \n {1}".format(total_count,url))
开始爬虫,爬虫函数
def craw():
global url,containerID,since_id
http = requests.get(url, headers=headers)
json_data = json.loads(http.text)
if('since_id' in json_data['data']['cardlistInfo']):
since_id = str(json_data['data']['cardlistInfo']['since_id'])
else:
print('暂无更多图片,已爬取完毕。')
os._exit(0)
print("正在分析下载第{0}篇微博图片, 总共需要下载{1}, 还需要下载{2}, SinceId:{3}".format((count + 1) * 10, weibo_count,weibo_count - (count * 10), since_id))
for i in range(0, len(json_data['data']['cards'])):
print(http.text)
if ('mblog' in json_data['data']['cards'][i]):
if ('pics' in json_data['data']['cards'][i]['mblog']):
for j in range(0, len(json_data['data']['cards'][i]['mblog']['pics'])):
print(http.text)
print(i, j)
src = json_data['data']['cards'][i]['mblog']['pics'][j]['large']['url']
# _thread.start_new_thread(saveImage, (src,))
# time.sleep(0.3)
saveImage(src)
for count in range(0,weibo_count):#根据这个 微博博主 的微博数量进行循环
if (count == 0):#如果是第一次的话则不附带since_id参数 因为没有
url = "https://m.weibo.cn/api/container/getIndex?containerid=" + containerID
else:
url = "https://m.weibo.cn/api/container/getIndex?containerid=" + containerID + "&since_id="+ since_id
try:#使用try避免第一次因为网络问题失败
craw()#开始爬取
except:
craw()
到这就写完了
下面是所有代码
(懒人区)
import _thread
import os
from urllib import parse
import requests
import json
import urllib
save_path = 'D:/weibo_images/'
weibo_id = '6524978930'
download = 0
total_count = 0
headers = {
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Mobile Safari/537.36',
}
def get_ContainerIDAndCount_Fromcookie(id):
global headers
request = requests.get('https://m.weibo.cn/u/'+id,headers=headers)
#request.raw.headers.getlist('Set-Cookie')
containerID = parse.unquote(request.cookies['M_WEIBOCN_PARAMS']).split('=')[1].split('&')[0]
request = requests.get('https://m.weibo.cn/api/container/getIndex?type=uid&value='+ id +'&containerid=' + containerID, headers=headers)
json_temp = json.loads(request.text)
containerid = json_temp['data']['tabsInfo']['tabs'][1]['containerid']
request = requests.get("https://m.weibo.cn/api/container/getIndex?containerid=" + containerid,headers=headers)
json_temp = json.loads(request.text)
count = json_temp['data']['cardlistInfo']['total']
return containerid,count
def saveImage(url):
global total_count, download
total_count += 1
file = 'url.txt'
with open(file, 'a+') as f:
f.write(url + '\n')
try:
if (download == 1):
urllib.request.urlretrieve(url, save_path + os.path.basename(url))
print("正在下载第:{0}张 \n {1}".format(total_count,url))
except:
print("下载失败,重新下载。")
if (download == 1):
urllib.request.urlretrieve(url, save_path + os.path.basename(url))
print("正在下载第:{0}张 \n {1}".format(total_count,url))
def craw():
global url,containerID,since_id
http = requests.get(url, headers=headers)
json_data = json.loads(http.text)
if('since_id' in json_data['data']['cardlistInfo']):
since_id = str(json_data['data']['cardlistInfo']['since_id'])
else:
print('暂无更多图片,已爬取完毕。')
os._exit(0)
print("正在分析下载第{0}篇微博图片, 总共需要下载{1}, 还需要下载{2}, SinceId:{3}".format((count + 1) * 10, weibo_count,weibo_count - (count * 10), since_id))
for i in range(0, len(json_data['data']['cards'])):
print(http.text)
if ('mblog' in json_data['data']['cards'][i]):
if ('pics' in json_data['data']['cards'][i]['mblog']):
for j in range(0, len(json_data['data']['cards'][i]['mblog']['pics'])):
print(http.text)
print(i, j)
src = json_data['data']['cards'][i]['mblog']['pics'][j]['large']['url']
# _thread.start_new_thread(saveImage, (src,))
# time.sleep(0.3)
saveImage(src)
containerID, weibo_count = get_ContainerIDAndCount_Fromcookie(weibo_id)
print(containerID, weibo_count)
for count in range(0,weibo_count):
if (count == 0):
url = "https://m.weibo.cn/api/container/getIndex?containerid=" + containerID
else:
url = "https://m.weibo.cn/api/container/getIndex?containerid=" + containerID + "&since_id="+ since_id
try:
craw()
except:
craw()
OK,本文结束,有问题评论区留言或者QQ群讨论。

原文链接:【Python】微博爬虫代码详解
Macro's Blog 版权所有,转载请注明出处。




 好用就行
好用就行 ,时光荏苒啊。
,时光荏苒啊。

学会了,感谢博主
我爬取的时候,用json.get(“data”).get(“cardlistInfo”)的方法,爬不到since_id,纠结好多种方法,返回的since_id都是none
可能微博更改了返回方式了,把since_id以其他方式返回了也说不定
since_id 在网页上查看是有的,但是返回的是none。后来我搜微博手机版,换了一个网页,返回的是page,就用旧方法解决了。感谢回复